
MII-LLM an indipendent AI research community
We are specializing ourselves in training, evaluating, developing and deploying AI systems. All our services are supported by Seeweb cloud provider. We ♥ Italy and open source.
Maestrale
Is a 7 billion open source model fine tuned for producing good Italian both semantically and syntatically. It is one of the best model for Italian language as is shown in the LLM Arena leaderboard ITA from indigo.ai competing with the best closed model from Openai, Anthropic and Google and it is able to produce high quality text in a wide range of domains. Maestrale is able to integrate with tools via json and API calls and has reasoning capabilities. Discover more on the api documentation.


Propaganda
Propaganda is an open-source initiative dedicated to assessing and generating political bias in Large Language Models (LLMs). It offers comprehensive suites designed for evaluating political bias, developing datasets to introduce political bias into LLMs, and has also released two specific LLMs: Propaganda-dx, tailored for conservative bias, and Propaganda-sx, aimed at liberal bias.
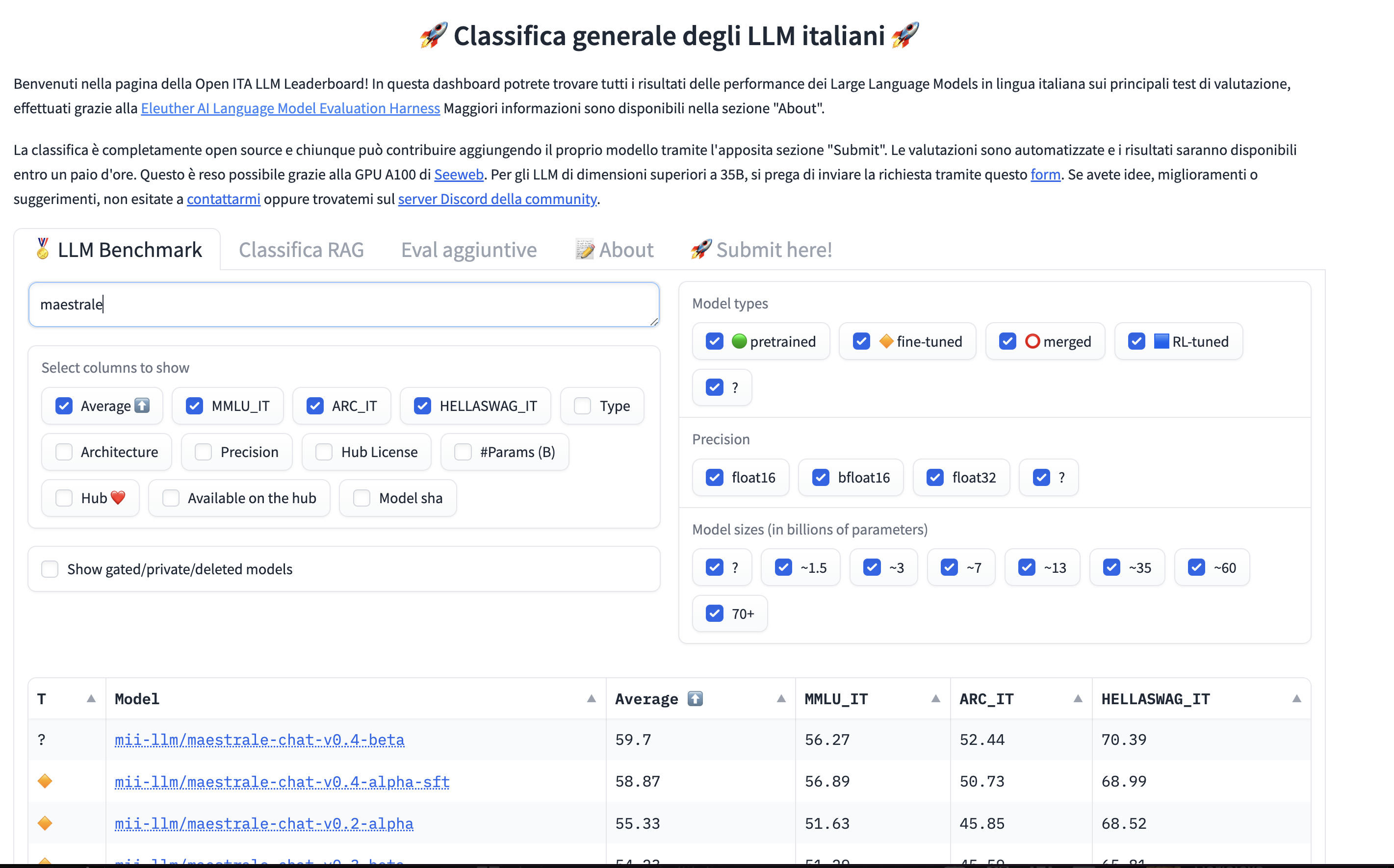
Italian LLMs leaderboard
The ranking of the open source Italian LLMs on reproducible evaluation benchmarks as mmlu_it, arc_c_it, hellaswag_it and others.
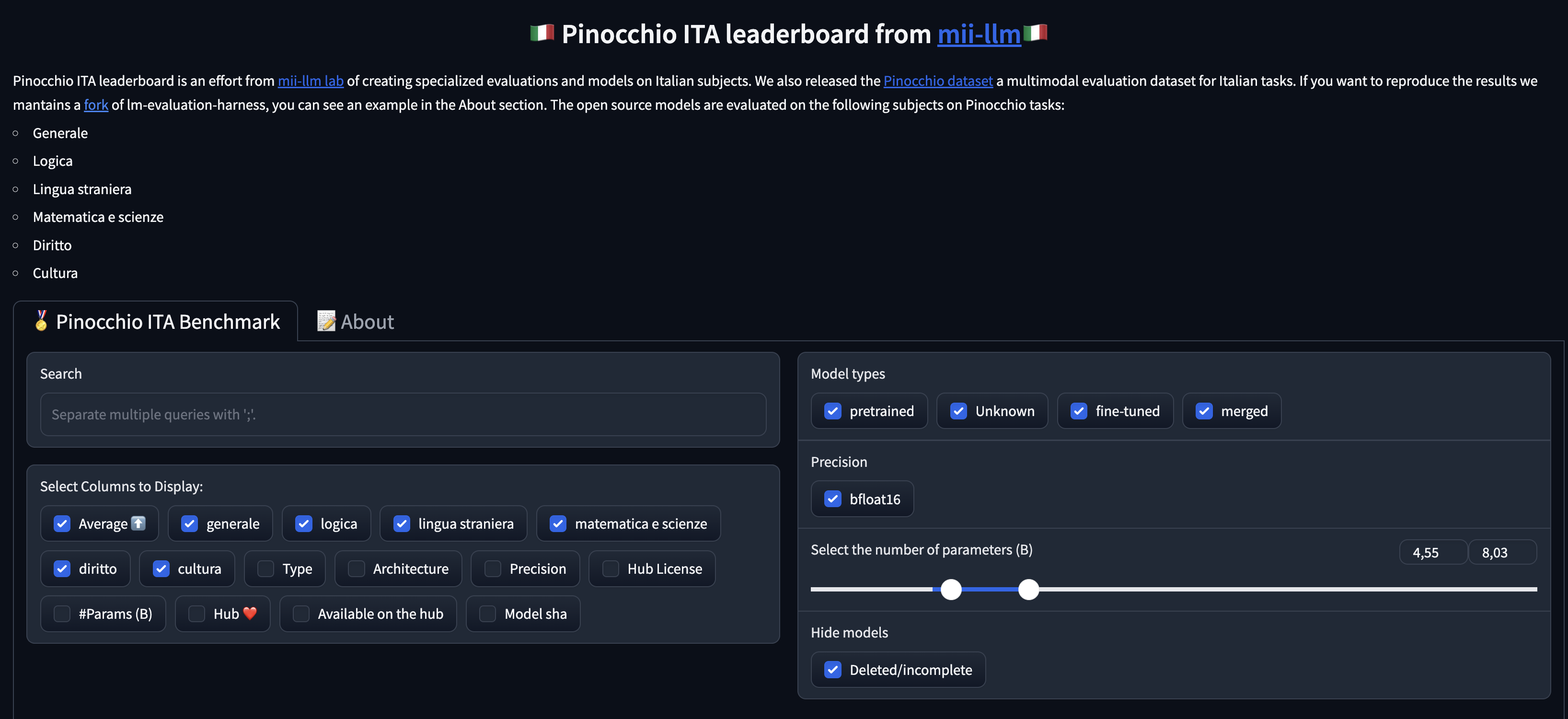
Pinocchio ITA leaderboard
Specialized benchmarks on specific topics as logic, math, law, foreign language and culture for Italian finetuned LLMs
Open source contributions
We have many thousands of downloads. Here a list of our most important contributions to the ML/AI open source community
Propaganda
Propaganda is an open-source initiative dedicated to assessing and generating political bias in Large Language Models (LLMs).
lm-evaluation-harness
We contribute to add mmlu and arc_c evaluation benchmark for Italian based tasks. Our bechmarks are now used by many LLMs groups for evaluating Italian based LLMs
Zefiro trilogy
One of the first completely open source Italian model in three versions: continual pre-trained, SFT and DPO
Gazzetta Ufficiale
The entire corpus of the current Italian laws as an open source dataset
Ultrafeedback ITA
Translated version of the ultrafeedback dataset for SFT fine tuning
Ultrafeedback binarized ITA
Translated version eng to ita of the popular ultrafeedback binarized dataset for DPO fine tuning.
Usenet conversations
The biggest dataset of real conversations in the Italian language from usenet
mmlu-pro
We tranlated the mmlu-pro dataset to Italian and contributed to integrate into the lm-eval command for evaluating Italian LLM on difficult tasks
Maestrale series
A series of open source LLMs a fine tuned versions of mistral 7 Billion for producing Italian
Pinocchio Eval dataset
A multimodal and text dataset for evaluating LLMs on Italian tasks
lm-evaluation-harness fork
A fork of lm-evaluation-harness with Italian specific tasks: mmlu arc-c hellaswag pinocchio-law, pinocchio-logic, pinocchio-math and reasoning like mmlu-pro-ita